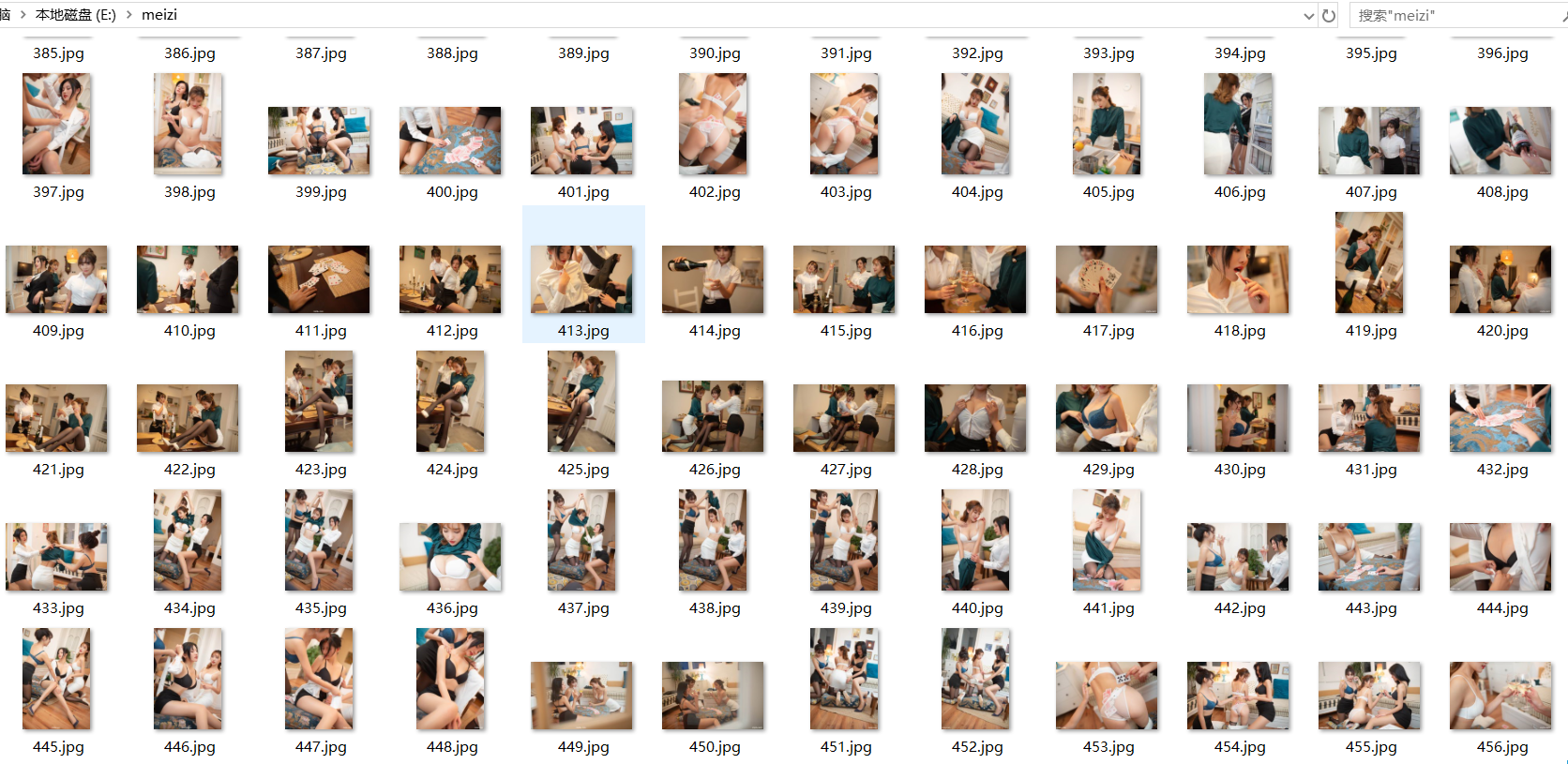
在前端,学习到了通过Python提供的HTTP请求库来抓取图片,在实际的爬虫中,大致的流程也是这样,但是在实际开发过程中会结合一些现成的爬虫库来帮助我们快速开发。
安装Scrapy
当然,除了Scrapy还有其他的爬虫库,如:Crawley、Portia、PyQuery等,只是这个更加强大一些。我们要使用它,当然得先得到它,这里就开始安装Scrapy框架,执行安装命令pip install Scrapy
Looking in indexes: https://pypi.doubanio.com/simple/
Collecting Scrapy
Downloading https://pypi.doubanio.com/packages/92/2a/5144dacee62e344e691a51e4cdf0f7c4ff5ae86feb9bf0557da26b8bd1d5/Scrapy-2.0.0-py2.py3-none-any.whl (241kB)
|████████████████████████████████| 245kB 2.2MB/s
Collecting Twisted>=17.9.0 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/0b/95/5fff90cd4093c79759d736e5f7c921c8eb7e5057a70d753cdb4e8e5895d7/Twisted-19.10.0.tar.bz2 (3.1MB)
|████████████████████████████████| 3.1MB ...
Collecting parsel>=1.5.0 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/86/c8/fc5a2f9376066905dfcca334da2a25842aedfda142c0424722e7c497798b/parsel-1.5.2-py2.py3-none-any.whl
Requirement already satisfied: cssselect>=0.9.1 in d:\programs\python\python38-32\lib\site-packages (from Scrapy) (1.1.0)
Collecting protego>=0.1.15 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/db/6e/bf6d5e4d7cf233b785719aaec2c38f027b9c2ed980a0015ec1a1cced4893/Protego-0.1.16.tar.gz (3.2MB)
|████████████████████████████████| 3.2MB 819kB/s
Collecting PyDispatcher>=2.0.5 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/cd/37/39aca520918ce1935bea9c356bcbb7ed7e52ad4e31bff9b943dfc8e7115b/PyDispatcher-2.0.5.tar.gz
Collecting zope.interface>=4.1.3 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/61/44/fe14da075671b756172660d5dc93a22beb9814b9b6f374b62aaa427907c5/zope.interface-4.7.1-cp38-cp38-win32.whl (132kB)
|████████████████████████████████| 133kB 6.4MB/s
Collecting cryptography>=2.0 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/74/e1/6e360b4dbd2a63c1f506402bfa6fa56aa5826337830d8ee86e5e2ec9457b/cryptography-2.8-cp38-cp38-win32.whl (1.3MB)
|████████████████████████████████| 1.3MB ...
Collecting pyOpenSSL>=16.2.0 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/9e/de/f8342b68fa9e981d348039954657bdf681b2ab93de27443be51865ffa310/pyOpenSSL-19.1.0-py2.py3-none-any.whl (53kB)
|████████████████████████████████| 61kB ...
Collecting service-identity>=16.0.0 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/e9/7c/2195b890023e098f9618d43ebc337d83c8b38d414326685339eb024db2f6/service_identity-18.1.0-py2.py3-none-any.whl
Requirement already satisfied: w3lib>=1.17.0 in d:\programs\python\python38-32\lib\site-packages (from Scrapy) (1.21.0)
Collecting queuelib>=1.4.2 (from Scrapy)
Downloading https://pypi.doubanio.com/packages/4c/85/ae64e9145f39dd6d14f8af3fa809a270ef3729f3b90b3c0cf5aa242ab0d4/queuelib-1.5.0-py2.py3-none-any.whl
Requirement already satisfied: lxml>=3.5.0 in d:\programs\python\python38-32\lib\site-packages (from Scrapy) (4.4.2)
Collecting constantly>=15.1 (from Twisted>=17.9.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/b9/65/48c1909d0c0aeae6c10213340ce682db01b48ea900a7d9fce7a7910ff318/constantly-15.1.0-py2.py3-none-any.whl
Collecting incremental>=16.10.1 (from Twisted>=17.9.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/f5/1d/c98a587dc06e107115cf4a58b49de20b19222c83d75335a192052af4c4b7/incremental-17.5.0-py2.py3-none-any.whl
Collecting Automat>=0.3.0 (from Twisted>=17.9.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/dd/83/5f6f3c1a562674d65efc320257bdc0873ec53147835aeef7762fe7585273/Automat-20.2.0-py2.py3-none-any.whl
Collecting hyperlink>=17.1.1 (from Twisted>=17.9.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/7f/91/e916ca10a2de1cb7101a9b24da546fb90ee14629e23160086cf3361c4fb8/hyperlink-19.0.0-py2.py3-none-any.whl
Collecting PyHamcrest>=1.9.0 (from Twisted>=17.9.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/40/16/e54cc65891f01cb62893540f44ffd3e8dab0a22443e1b438f1a9f5574bee/PyHamcrest-2.0.2-py3-none-any.whl (52kB)
|████████████████████████████████| 61kB ...
Collecting attrs>=17.4.0 (from Twisted>=17.9.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/a2/db/4313ab3be961f7a763066401fb77f7748373b6094076ae2bda2806988af6/attrs-19.3.0-py2.py3-none-any.whl
Requirement already satisfied: six>=1.5.2 in c:\users\lenovo\appdata\roaming\python\python38\site-packages (from parsel>=1.5.0->Scrapy) (1.14.0)
Requirement already satisfied: setuptools in d:\programs\python\python38-32\lib\site-packages (from zope.interface>=4.1.3->Scrapy) (41.2.0)
Collecting cffi!=1.11.3,>=1.8 (from cryptography>=2.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/0a/e4/cb57bf30f98fc7c36c0db2759b875d3990ad531a8f2e9e535da2bdcc138f/cffi-1.14.0-cp38-cp38-win32.whl (165kB)
|████████████████████████████████| 174kB 2.2MB/s
Collecting pyasn1-modules (from service-identity>=16.0.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/95/de/214830a981892a3e286c3794f41ae67a4495df1108c3da8a9f62159b9a9d/pyasn1_modules-0.2.8-py2.py3-none-any.whl (155kB)
|████████████████████████████████| 163kB 2.2MB/s
Collecting pyasn1 (from service-identity>=16.0.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/62/1e/a94a8d635fa3ce4cfc7f506003548d0a2447ae76fd5ca53932970fe3053f/pyasn1-0.4.8-py2.py3-none-any.whl (77kB)
|████████████████████████████████| 81kB 2.6MB/s
Requirement already satisfied: idna>=2.5 in d:\programs\python\python38-32\lib\site-packages (from hyperlink>=17.1.1->Twisted>=17.9.0->Scrapy) (2.8)
Collecting pycparser (from cffi!=1.11.3,>=1.8->cryptography>=2.0->Scrapy)
Downloading https://pypi.doubanio.com/packages/ae/e7/d9c3a176ca4b02024debf82342dab36efadfc5776f9c8db077e8f6e71821/pycparser-2.20-py2.py3-none-any.whl (112kB)
|████████████████████████████████| 112kB 2.2MB/s
Installing collected packages: zope.interface, constantly, incremental, attrs, Automat, hyperlink, PyHamcrest, Twisted, parsel, protego, PyDispatcher, pycparser, cffi, cryptography, pyOpenSSL, pyasn1, pyasn1-modules, service-identity, queuelib, Scrapy
Running setup.py install for Twisted ... done
Running setup.py install for protego ... done
Running setup.py install for PyDispatcher ... done
Successfully installed Automat-20.2.0 PyDispatcher-2.0.5 PyHamcrest-2.0.2 Scrapy-2.0.0 Twisted-19.10.0 attrs-19.3.0 cffi-1.14.0 constantly-15.1.0 cryptography-2.8 hyperlink-19.0.0 incremental-17.5.0 parsel-1.5.2 protego-0.1.16 pyOpenSSL-19.1.0 pyasn1-0.4.8 pyasn1-modules-0.2.8 pycparser-2.20 queuelib-1.5.0 service-identity-18.1.0 zope.interface-4.7.1
WARNING: You are using pip version 19.2.3, however version 20.0.2 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
不出意外的话,就像我这样,就安装成功了。这时候我们在命令窗口输入Scrapy则会有这样的显示
Scrapy 2.0.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
用Scrapy创建一个爬虫项目
这时候,我们就可以借助Scrapy来创建项目了。新建一个目录,通过cmd命令行进入到这个目录里面,执行创建命令scrapy startproject spider
E:\>scrapy startproject myspider
New Scrapy project 'myspider', using template directory 'd:\programs\python\python38-32\lib\site-packages\scrapy\templates\project', created in:
E:\myspider
You can start your first spider with:
cd myspider
scrapy genspider example example.com
我们在继续借助于Scrapy创建一个Spider
E:\myspider>scrapy genspider meizitu www.mzitu.com
Created spider 'meizitu' using template 'basic' in module:
myspider.spiders.meizitu
最后的结构是这样的
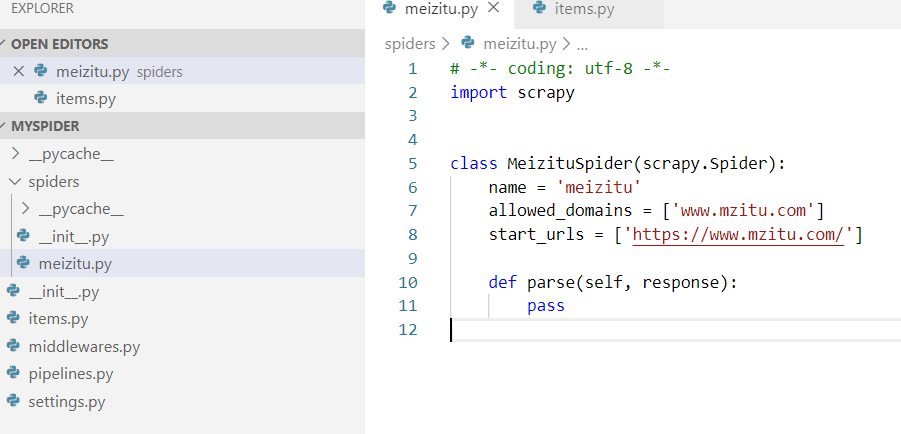 这里需要咱们先关注
这里需要咱们先关注meizitu.py和items.py两个文件,先给items.py加入两个字段属性
class MyspiderItem(scrapy.Item):
name=scrapy.Field()
img_url=scrapy.Field()
referer=scrapy.Field() #防止请求时防盗链
因为我是用的VS Code编辑的代码,如果想要调试可以再launch.json中配置,也可以在同目录下新建一个启动的py文件,代码如下
from scrapy.cmdline import execute
import os
# 获取当前文件路径
dirpath = os.path.dirname(os.path.abspath(__file__))
#切换到scrapy项目路径下
os.chdir(dirpath[:dirpath.rindex("\\")])
# 启动爬虫,第三个参数为爬虫name
execute(['scrapy','crawl','meizitu'])
按F5即可运行,这时候,可能会遇到INFO: Ignoring response <403 https://www.mzitu.com>: HTTP status code is not handled or not allowed ,如果有遇到的话,那么就在setting.py加入配置
HTTPERROR_ALLOWED_CODES = [403]
但是一般403是禁止访问,大概率来说是服务端有反爬机制,所以这时候,我们需要用到User-Agent,这里先加入一些常用的User-Agent标识
USER_AGENT_LIST=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
然后在我们的middlewares.py中自定义中间件
from settings import USER_AGENT_LIST
import random
class RotateUserAgentMiddleware(object):
def process_request(self, request, spider):
ua = random.choice(USER_AGENT_LIST)
request.headers.setdefault('User-Agent', ua)
再在setting.py中启用刚才定义的中间件
DOWNLOADER_MIDDLEWARES ={
'myspider.middlewares.RotateUserAgentMiddleware': 403,
}
现在是可以正常抓取网页了,现在我们需要解析一些获取到的html
class MeizituSpider(scrapy.Spider):
name = 'meizitu'
allowed_domains = ['www.mzitu.com']
start_urls = ['https://www.mzitu.com/209540']
def parse(self, response):
print(response.request.url)
a=response.css(".main-image a")
for la in a:
item=MyspiderItem()
item['img_url']=la.css('img::attr(src)').extract()
item['referer']=response.request.url;
yield item #此处不能少
我们在再Pipeline编写保存图片逻辑
class MyspiderPipeline(object):
index = 1
def process_item(self, item, spider):
print(item['img_url'])
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE',
'Referer':item['referer']
}
result = requests.get(item['img_url'][0],headers=headers)
with open("E:\\meizi\\" + str(self.index) + ".jpg", 'wb') as f:
f.write(result.content)
f.close()
self.index += 1
return item
此处是headers是为了处理反爬虫和盗链的问题。这时候,我们的图片是可以正常的下载了、但是目前仅能下载
在setting.py中加入刚才的Pipeline
ITEM_PIPELINES = {
'myspider.pipelines.MyspiderPipeline': 200,
}
现在运行,是可以正常下载图片了,但是仅能下载单张图片,我们怎么能批量下载呢?简单,就是在抓取当个页面时,将页面解析到的url在放到scrapy.Request里面,就可以循环下载了,最后MeizituSpider的完整代码如下。
class MeizituSpider(scrapy.Spider):
name = 'meizitu'
allowed_domains = ['www.mzitu.com']
start_urls = ['https://www.mzitu.com/209540']
def parse(self, response):
print(response.request.url)
a=response.css(".main-image a")
for la in a:
item=MyspiderItem()
item['img_url']=la.css('img::attr(src)').extract()
item['referer']=response.request.url;
yield item
next_urls = response.css('.pagenavi a')[-1].css('a::attr(href)').extract_first()
yield scrapy.Request(url=next_urls,callback=self.parse)
此时来看看我们的福利吧