我觉得人就要知足常乐,时刻给自己一点奖励以示回馈自己。所以,这里我就要开始给大家福利了–下载妹子图。
环境准备
首先我先简单的介绍一下基本的东西,咱们看图说话
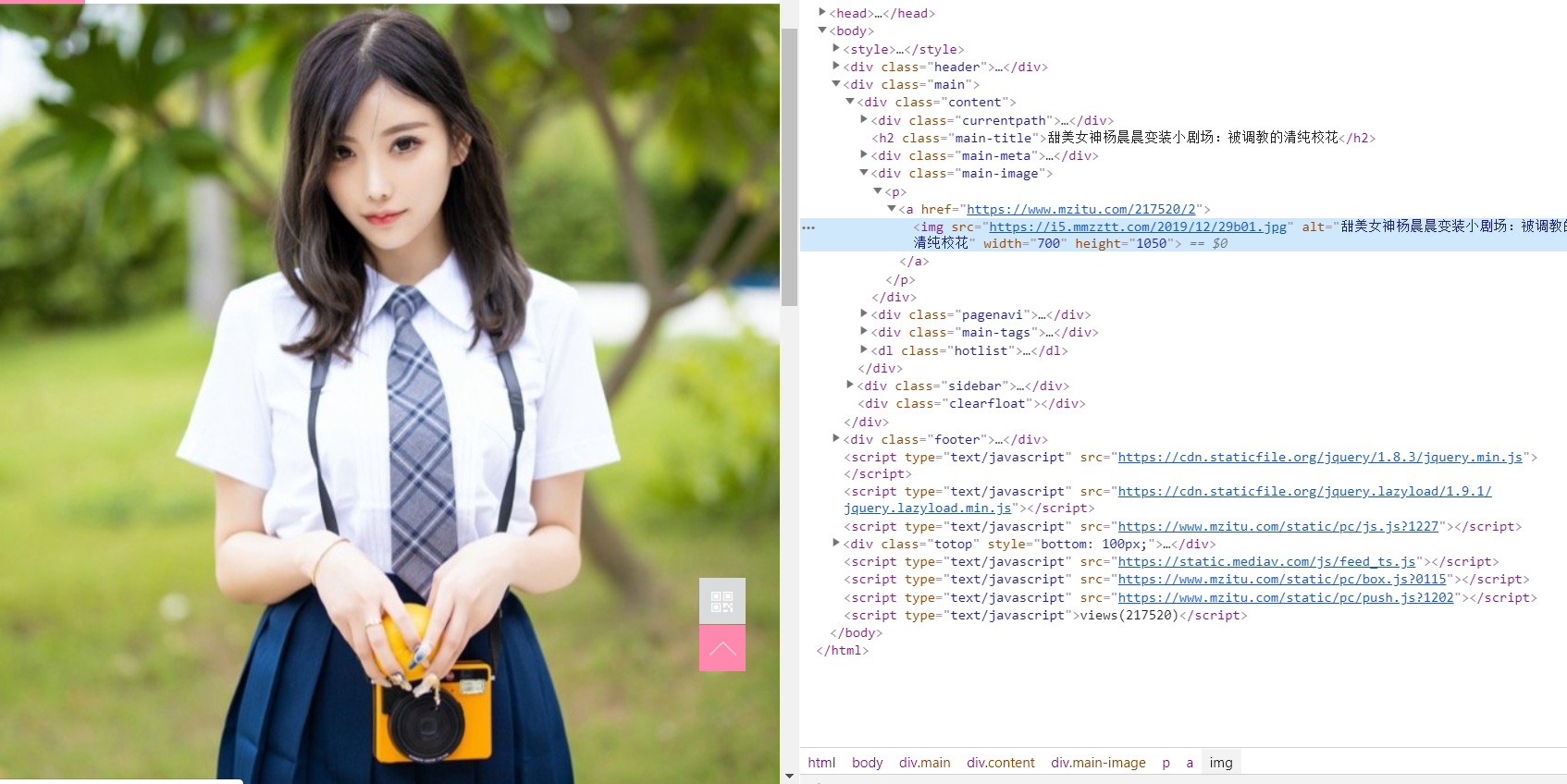 上面的图片是我在谷歌浏览器得到的效果。左边是美女图片,右边是我们通过浏览器访问地址得到的
上面的图片是我在谷歌浏览器得到的效果。左边是美女图片,右边是我们通过浏览器访问地址得到的html代码。我们要下载图片,就需要从众多html找到我们的漂亮妹子才行.所以我们需要requests-html这个东东,它的github地址是https://github.com/psf/requests-html。然后我们就安装它:
pip install requests-html
执行命令后,就会为我们下载相应的依赖包并解压:
Looking in indexes: https://pypi.doubanio.com/simple/
Collecting requests-html
Downloading https://pypi.doubanio.com/packages/24/bc/a4380f09bab3a776182578ce6b2771e57259d0d4dbce178205779abdc347/requests_html-0.10.0-py3-none-any.whl
Collecting bs4 (from requests-html)
Downloading https://pypi.doubanio.com/packages/10/ed/7e8b97591f6f456174139ec089c769f89a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz
Collecting parse (from requests-html)
Downloading https://pypi.doubanio.com/packages/4a/ea/9a16ff916752241aa80f1a5ec56dc6c6defc5d0e70af2d16904a9573367f/parse-1.14.0.tar.gz
Collecting fake-useragent (from requests-html)
Downloading https://pypi.doubanio.com/packages/d1/79/af647635d6968e2deb57a208d309f6069d31cb138066d7e821e575112a80/fake-useragent-0.1.11.tar.gz
Collecting requests (from requests-html)
Downloading https://pypi.doubanio.com/packages/51/bd/23c926cd341ea6b7dd0b2a00aba99ae0f828be89d72b2190f27c11d4b7fb/requests-2.22.0-py2.py3-none-any.whl (57kB)
|████████████████████████████████| 61kB 1.3MB/s
Collecting pyquery (from requests-html)
Downloading https://pypi.doubanio.com/packages/78/43/95d42e386c61cb639d1a0b94f0c0b9f0b7d6b981ad3c043a836c8b5bc68b/pyquery-1.4.1-py2.py3-none-any.whl
Collecting w3lib (from requests-html)
Downloading https://pypi.doubanio.com/packages/6a/45/1ba17c50a0bb16bd950c9c2b92ec60d40c8ebda9f3371ae4230c437120b6/w3lib-1.21.0-py2.py3-none-any.whl
Collecting pyppeteer>=0.0.14 (from requests-html)
Downloading https://pypi.doubanio.com/packages/b0/16/a5e8d617994cac605f972523bb25f12e3ff9c30baee29b4a9c50467229d9/pyppeteer-0.0.25.tar.gz (1.2MB)
|████████████████████████████████| 1.2MB 819kB/s
Collecting beautifulsoup4 (from bs4->requests-html)
Downloading https://pypi.doubanio.com/packages/cb/a1/c698cf319e9cfed6b17376281bd0efc6bfc8465698f54170ef60a485ab5d/beautifulsoup4-4.8.2-py3-none-any.whl (106kB)
|████████████████████████████████| 112kB 297kB/s
Collecting idna<2.9,>=2.5 (from requests->requests-html)
Downloading https://pypi.doubanio.com/packages/14/2c/cd551d81dbe15200be1cf41cd03869a46fe7226e7450af7a6545bfc474c9/idna-2.8-py2.py3-none-any.whl (58kB)
|████████████████████████████████| 61kB 491kB/s
Collecting certifi>=2017.4.17 (from requests->requests-html)
Downloading https://pypi.doubanio.com/packages/b9/63/df50cac98ea0d5b006c55a399c3bf1db9da7b5a24de7890bc9cfd5dd9e99/certifi-2019.11.28-py2.py3-none-any.whl (156kB)
|████████████████████████████████| 163kB 273kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests->requests-html)
Downloading https://pypi.doubanio.com/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133kB)
|████████████████████████████████| 143kB 386kB/s
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 (from requests->requests-html)
Downloading https://pypi.doubanio.com/packages/e8/74/6e4f91745020f967d09332bb2b8b9b10090957334692eb88ea4afe91b77f/urllib3-1.25.8-py2.py3-none-any.whl (125kB)
|████████████████████████████████| 133kB 544kB/s
Collecting cssselect>0.7.9 (from pyquery->requests-html)
Downloading https://pypi.doubanio.com/packages/3b/d4/3b5c17f00cce85b9a1e6f91096e1cc8e8ede2e1be8e96b87ce1ed09e92c5/cssselect-1.1.0-py2.py3-none-any.whl
Collecting lxml>=2.1 (from pyquery->requests-html)
Downloading https://pypi.doubanio.com/packages/b7/f6/01a09f755e34aafe32a20f1de965527efa4244c7918cae0506a6d2016f1f/lxml-4.4.2-cp38-cp38-win32.whl (3.3MB)
|████████████████████████████████| 3.3MB 819kB/s
Requirement already satisfied: six>=1.4.1 in c:\users\lenovo\appdata\roaming\python\python38\site-packages (from w3lib->requests-html) (1.14.0)
Collecting pyee (from pyppeteer>=0.0.14->requests-html)
Downloading https://pypi.doubanio.com/packages/ad/d8/5608d571ffad3d7de0192b0b3099fe3f38d87c0817ebff3cee19264f0bc2/pyee-6.0.0-py2.py3-none-any.whl
Collecting websockets (from pyppeteer>=0.0.14->requests-html)
Downloading https://pypi.doubanio.com/packages/3c/b9/be61f1c129fcef9f54036d9b230ff5daf88a5557cc3193339e2806226093/websockets-8.1-cp38-cp38-win32.whl (65kB)
|████████████████████████████████| 71kB 1.5MB/s
Collecting appdirs (from pyppeteer>=0.0.14->requests-html)
Downloading https://pypi.doubanio.com/packages/56/eb/810e700ed1349edde4cbdc1b2a21e28cdf115f9faf263f6bbf8447c1abf3/appdirs-1.4.3-py2.py3-none-any.whl
Collecting tqdm (from pyppeteer>=0.0.14->requests-html)
Downloading https://pypi.doubanio.com/packages/72/c9/7fc20feac72e79032a7c8138fd0d395dc6d8812b5b9edf53c3afd0b31017/tqdm-4.41.1-py2.py3-none-any.whl (56kB)
|████████████████████████████████| 61kB 990kB/s
Collecting soupsieve>=1.2 (from beautifulsoup4->bs4->requests-html)
Downloading https://pypi.doubanio.com/packages/81/94/03c0f04471fc245d08d0a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl
Installing collected packages: soupsieve, beautifulsoup4, bs4, parse, fake-useragent, idna, certifi, chardet, urllib3, requests, cssselect, lxml, pyquery, w3lib, pyee, websockets, appdirs, tqdm, pyppeteer, requests-html
Running setup.py install for bs4 ... done
Running setup.py install for parse ... done
Running setup.py install for fake-useragent ... done
Running setup.py install for pyppeteer ... done
Successfully installed appdirs-1.4.3 beautifulsoup4-4.8.2 bs4-0.0.1 certifi-2019.11.28 chardet-3.0.4 cssselect-1.1.0 fake-useragent-0.1.11 idna-2.8 lxml-4.4.2 parse-1.14.0 pyee-6.0.0 pyppeteer-0.0.25 pyquery-1.4.1 requests-2.22.0 requests-html-0.10.0 soupsieve-1.9.5 tqdm-4.41.1 urllib3-1.25.8 w3lib-1.21.0 websockets-8.1
pip在我们安装Python的时候就自动为我们安装了.
熟悉requests-html的用法
在下载妹子之前,我们得先学会怎么用我们这个库。我们先根据requests-html官方教程走一遍,首先第一步是引入工具包:
from requests_html import HTMLSession
在之前的基础语法有提到过import引用模块,那么这里的form . import .又是怎么个意思呢?其实他也是引入模块。一般我们的模块会有很多工具类,但是我们不想import方式全部导入,只想导入我们要用到的类库,那么就需要用到这个了。这句的意思就是从requests_html模块中引入HTMLSession这个工具类。
第二步:实例化一个session对象(关于对象,后面会说到)
session = HTMLSession()
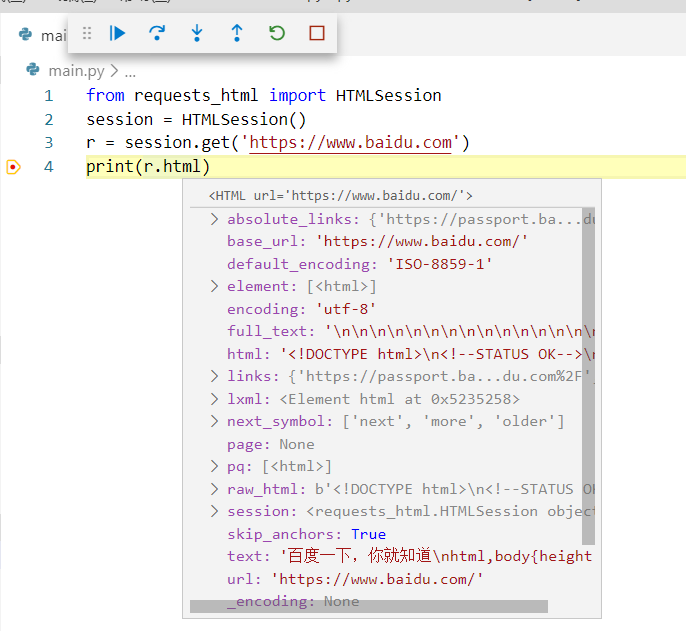
第三步:通过session去请求并获取网页的html代码:
r = session.get('https://www.baidu.com')
我们运行起来的相过如图:
下载妹子图咯
首先,我们需要请求网页:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.mzitu.com/217520')
最后对上面的代码进行分析,需要找到我们的img标签,获取其src的属性值:
img=r.html.find(".main-image",first=True).find('img',first=True)
print(img.attrs['src'])
最后我们可以得到一个图片地址https://i5.mmzztt.com/2019/12/29b01.jpg,大家可以直接复制到浏览器运行一下,看美不美?
然后我们借助Python自带的urllib3来下载:
response =http.request('GET', 'https://i5.mmzztt.com/2019/12/29b01.jpg',headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36",
"Referer": "https://www.mzitu.com/217520",
"Remote Address":"182.242.223.137:443",
"Referrer Policy":"no-referrer-when-downgrade"
})
open("D:/meizi/{}.jpg".format(uuid.uuid1()),'wb').write(response.data)
运行之后妹子就到我们的硬盘里面了.附上完整代码(只实现了功能,为优化):
from requests_html import HTMLSession
import urllib3
import uuid
session = HTMLSession()
http = urllib3.PoolManager()
for page in range(1, 55):
r = session.get('https://www.mzitu.com/217520/{}'.format(page))
img = r.html.find(".main-image", first=True).find('img', first=True)
response = http.request('GET', img.attrs['src'], headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36",
"Referer": "https://www.mzitu.com/217520",
"Remote Address": "182.242.223.137:443",
"Referrer Policy": "no-referrer-when-downgrade"
})
open("D:/meizi/{}.jpg".format(uuid.uuid1()), 'wb').write(response.data)
