大叔玩了三年的王者荣耀,打了三千多场,依然没有上过王者,究其因,还是因为太菜,可以说菜到了极致,所以大叔也就变得佛系了,偶尔玩几场娱乐娱乐一下,最近在看了一下王者荣耀的官网,感觉那些图片挺好看的,所以就想着把他下载下来当桌面吧。

那么,接下来就开始动手吧,先说一下我的环境
- Python 3.8.3
- Vs Code 1.48.0
- Requests 2.24.0
- Requests-HTML
- selenium
- PyQuery
如果Requests没有安装的话,需要先执行pip install Requests和pip install Requests-HTML安装
好了,现在我们来分析一下页面结构,先打开谷歌浏览器的开发者工具
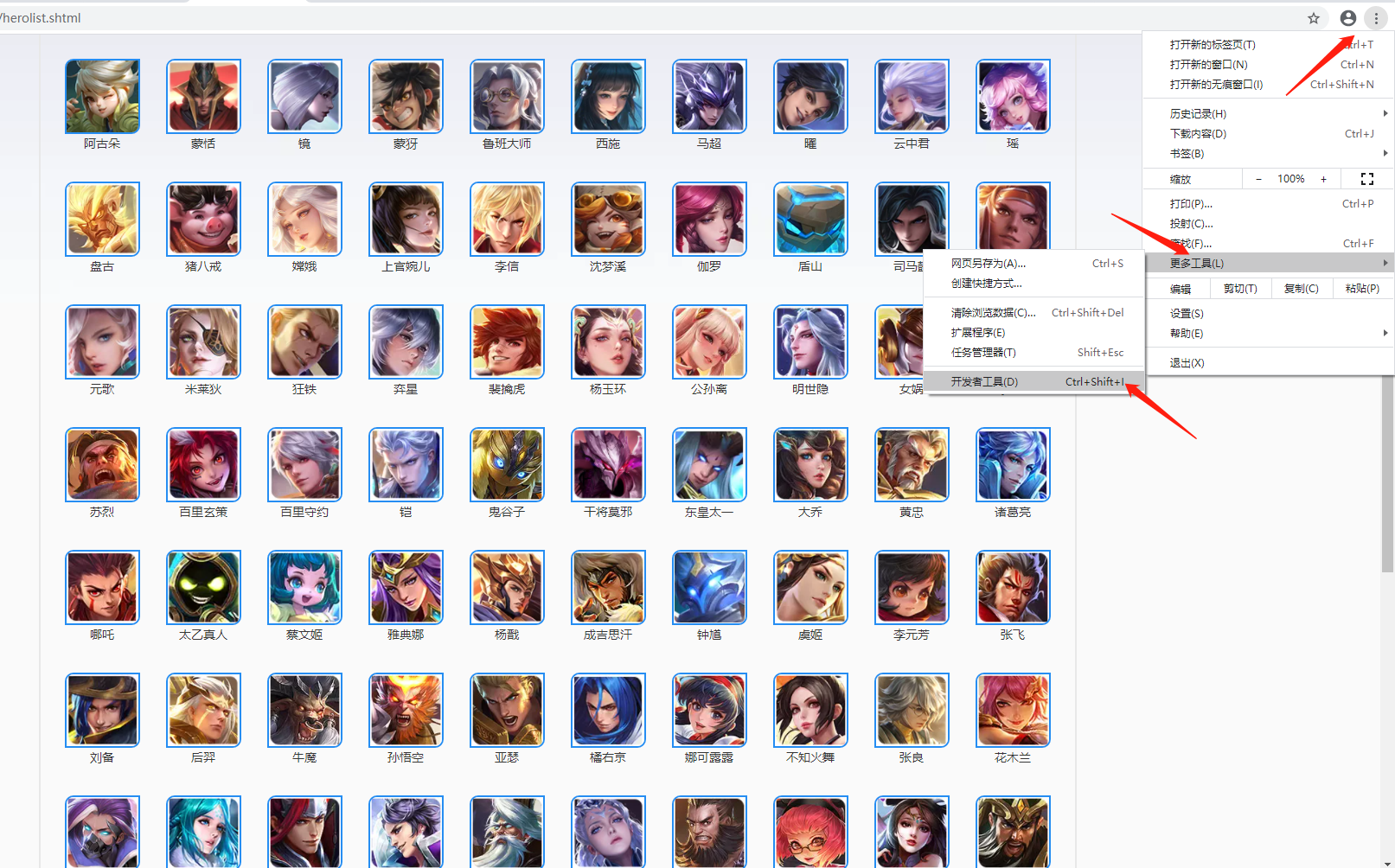
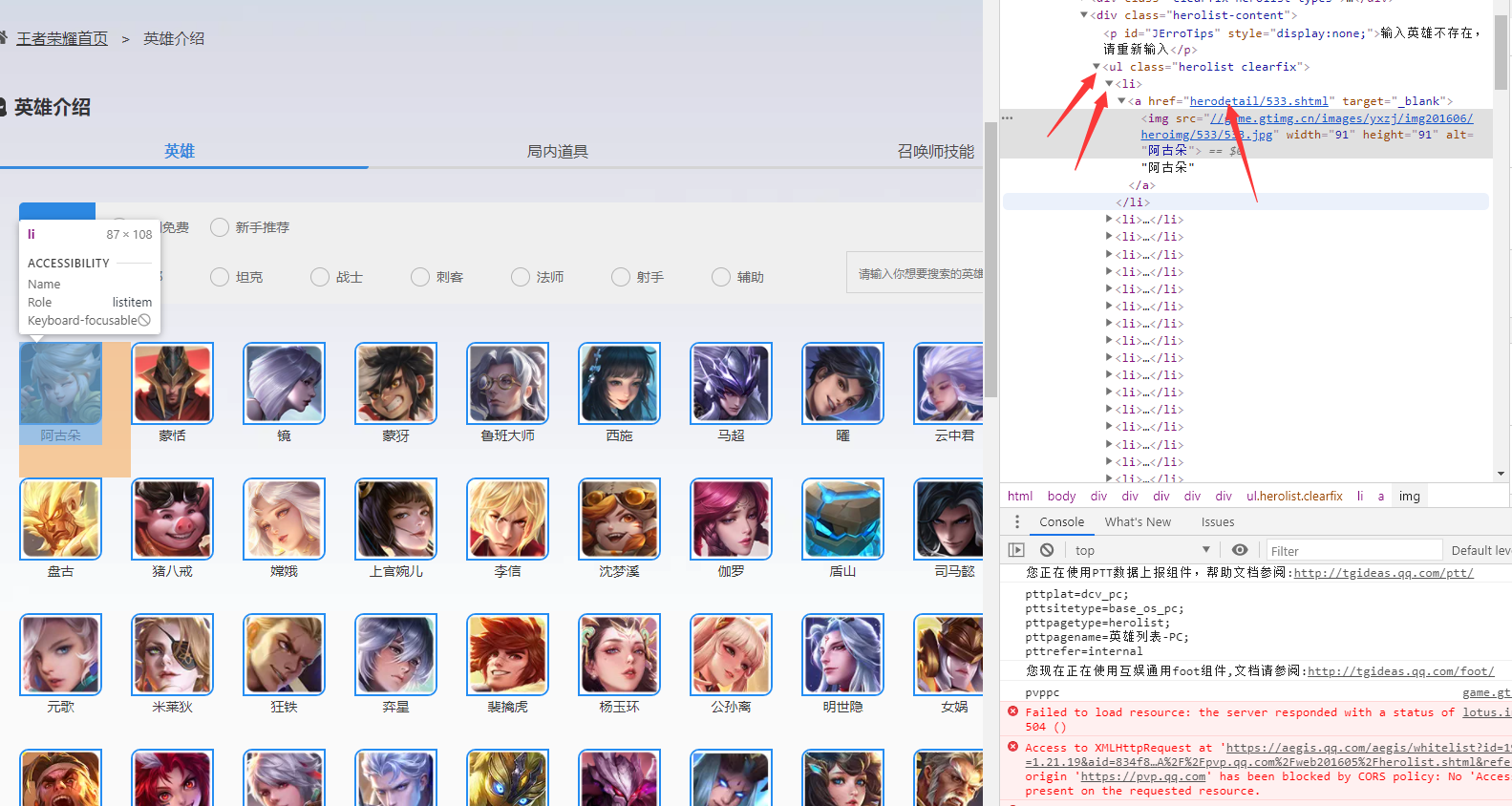
可以从图片中看到,英雄列表都在ul标签中,没有英雄都放在ul下的li标签中,这是渲染之后的效果,那么在渲染之前,它是通过获取的一个json数据到本地,我来看看这个json数据
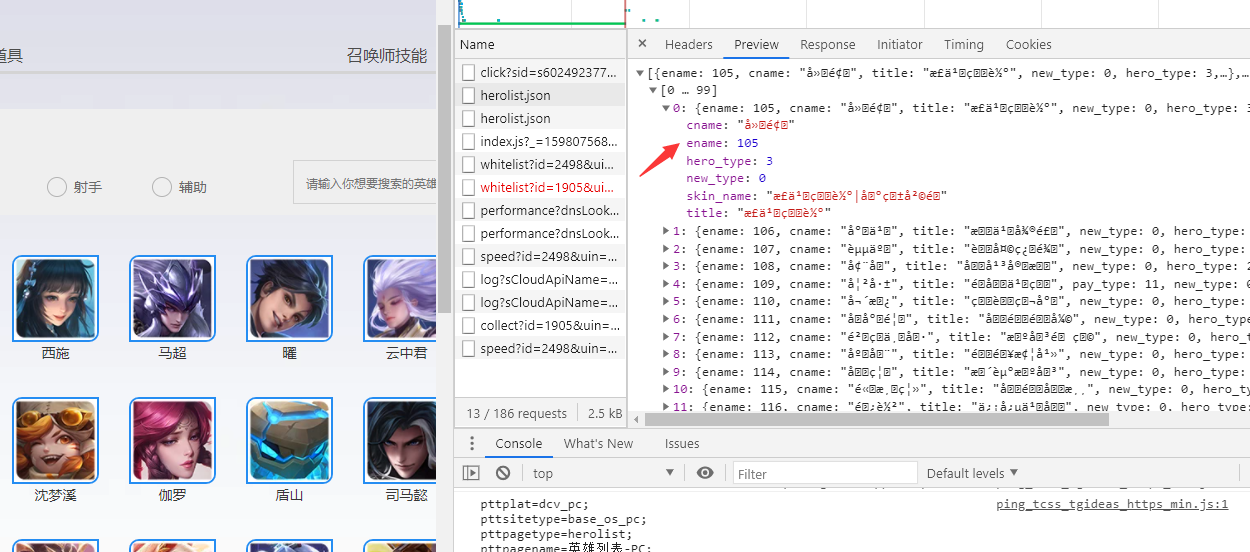
这里我们暂时只需要ename属性,这个页面我们就省去了解析html的工作
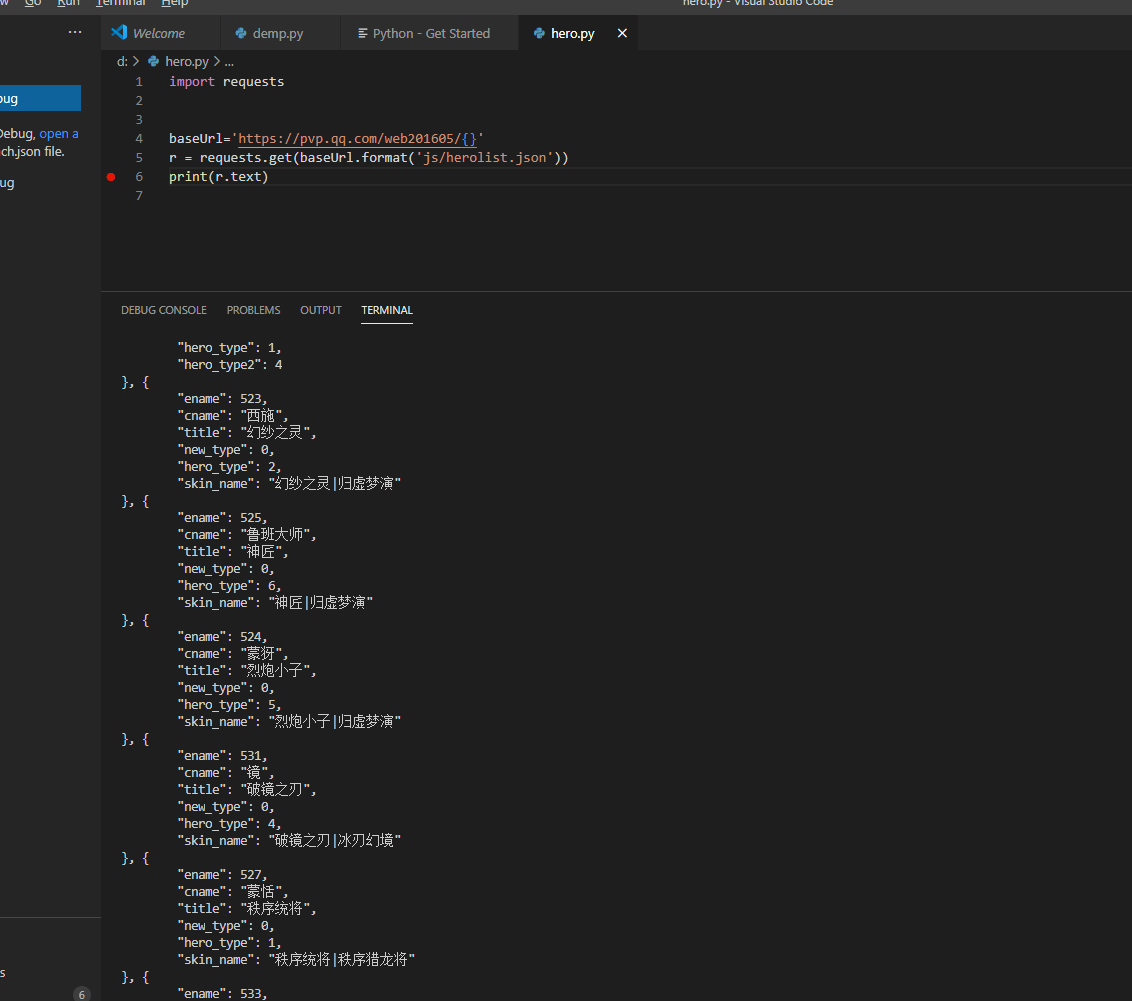
这里我们继续下个页面,看看我们想要的html结构
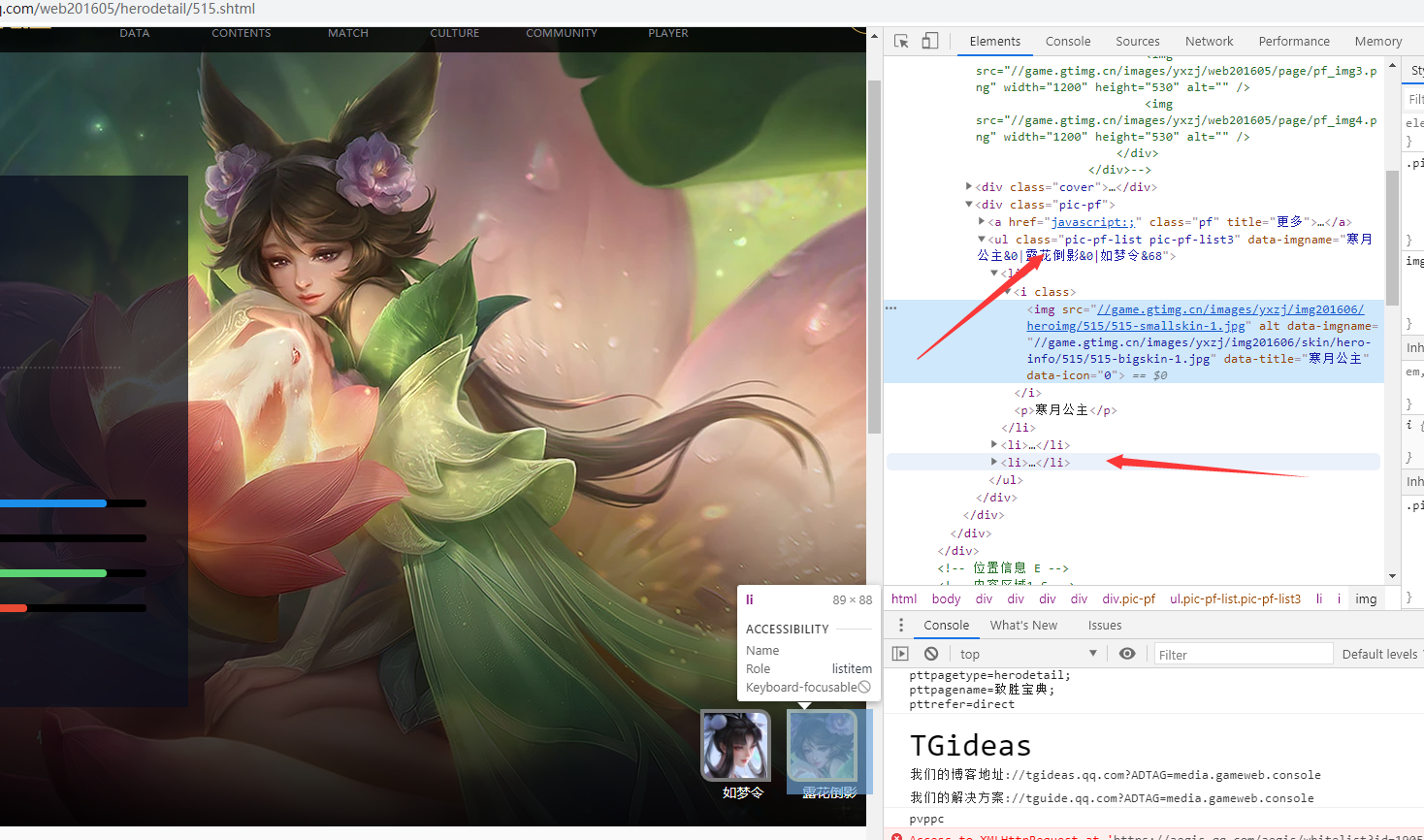
我们想要的图片路径就在class为pic-pf-list3的ul标签中,在li我们可以看到相应的图片,这里我们就需要借助Requests-HTML来解析html了。先来尝试个例子吧
import requests
import json
from requests_html import HTMLSession
session = HTMLSession()
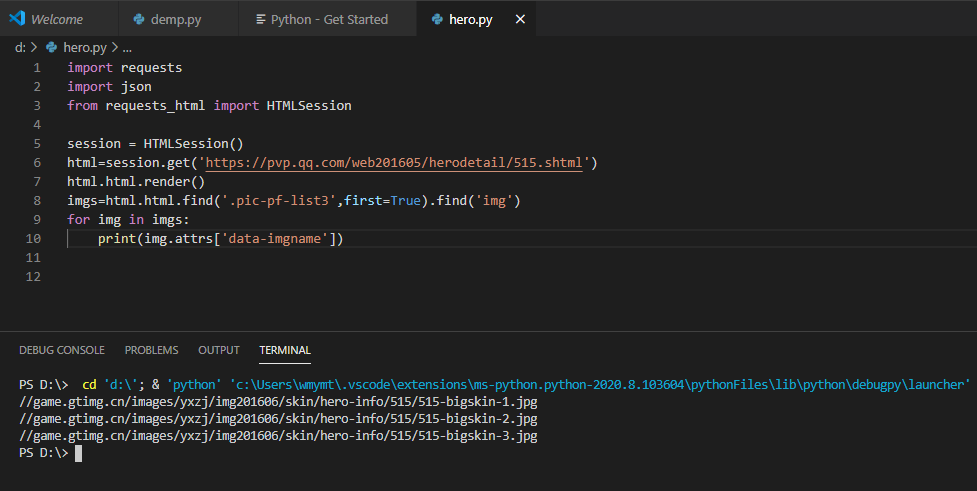
html=session.get('https://pvp.qq.com/web201605/herodetail/515.shtml')
html.html.render()
lis=html.html.find('.pic-pf-list3',first=True)
print(lis.html)
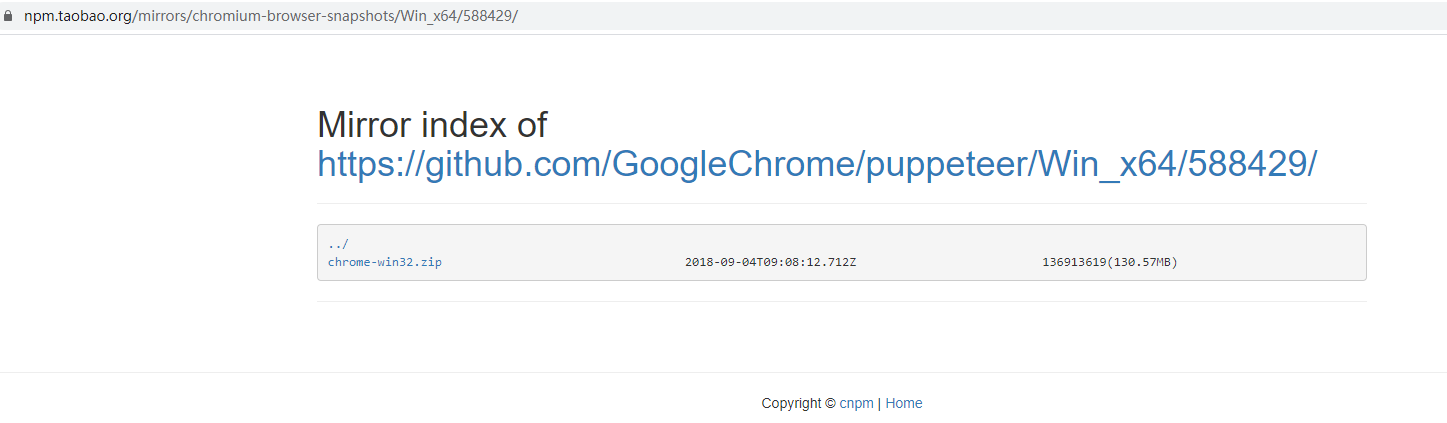
这时候如果是第一次调用render的话,会下载chromium,然后使用chromium来渲染页面,

我这边下载chromium是真的难受啊,你们可以换一种方式。这里我是在淘宝镜像去下载,然后解压到我的C:\Users\wmymt\AppData\Local\pyppeteer\pyppeteer\local-chromium\588429目录中
现在可以得到这样的结果

html中的data-imgname就是我们想要的图片
然后把我们获取到的图片下载到本地即可,来看看我们最后的代码吧
import requests
import json
from requests_html import HTMLSession
import time
import random
user_agents = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 ',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrow\
ser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4168.2 Safari/537.36'
]
base_url = 'https://pvp.qq.com/web201605/{}'
r = requests.get(base_url.format('js/herolist.json'))
res = json.loads(r.text)
session = HTMLSession()
img_cur_index = 1
for item in res:
try:
user_agent = random.choice(user_agents)
url=base_url.format(
'herodetail/'+str(item['ename'])+'.shtml')
print(url)
headers={'user-agent':user_agent,'origin':'https://pvp.qq.com','referer':url}
html = session.get(url,headers=headers)
html.html.render()
imgs = html.html.find('.pic-pf-list3', first=True).find('img')
for img in imgs:
print(img.attrs['data-imgname'])
img_content = requests.get('https:'+str(img.attrs['data-imgname']))
with open('D:/hero/'+str(img_cur_index)+'.jpg', 'wb')as f: # 将图片保存成文件
f.write(img_content.content)
img_cur_index = img_cur_index+1
time.sleep(1)
except:
pass

这里下载了部分图片,但是腾讯做了反爬虫,所以后面可能会超时,所以,我就换了一种方式,采用selenium来获取页面(selenium这里就不去回顾了,在之前学习的时候,有说到安装步骤和注意事项)
import requests
import json
from requests_html import HTMLSession
import time
import random
from selenium import webdriver
from pyquery import PyQuery as pq
base_url = 'https://pvp.qq.com/web201605/{}'
r = requests.get(base_url.format('js/herolist.json'))
res = json.loads(r.text)
session = HTMLSession()
img_cur_index = 1
browser = webdriver.Chrome()
for item in res:
try:
user_agent = random.choice(user_agents)
url=base_url.format(
'herodetail/'+str(item['ename'])+'.shtml')
print(url)
browser.get(url)
time.sleep(5)
doc=pq(browser.page_source)
html=doc('.pic-pf-list3')
imgs = html.find('img').items()
for img in imgs:
print(img.attr('data-imgname'))
img_content = requests.get('https:'+str(img.attr('data-imgname')))
with open('D:/hero/'+str(img_cur_index)+'.jpg', 'wb')as f: # 将图片保存成文件
f.write(img_content.content)
img_cur_index = img_cur_index+1
time.sleep(1)
except Exception as e:
print(str(e))
browser.quit()
现在就开始下载我们的英雄图片了
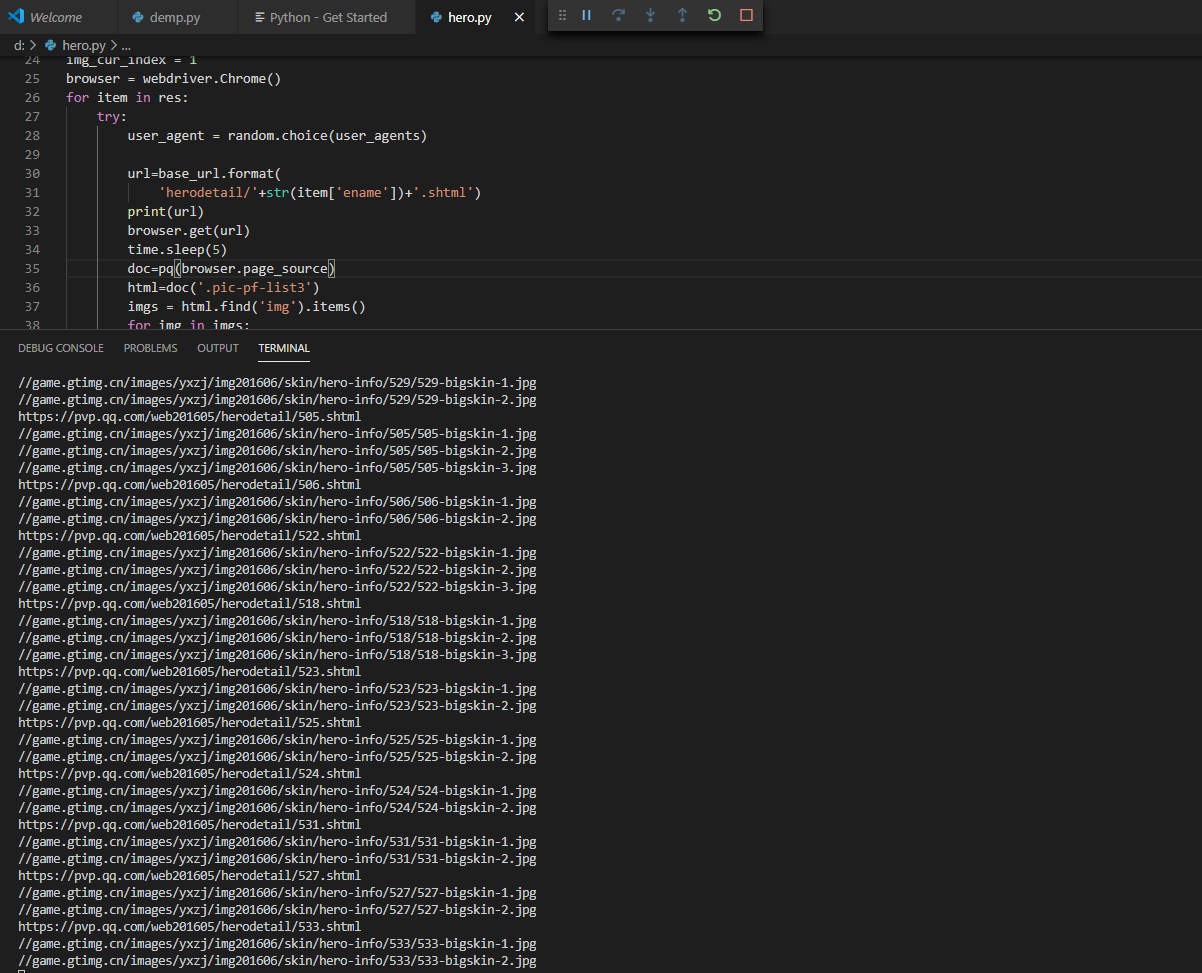
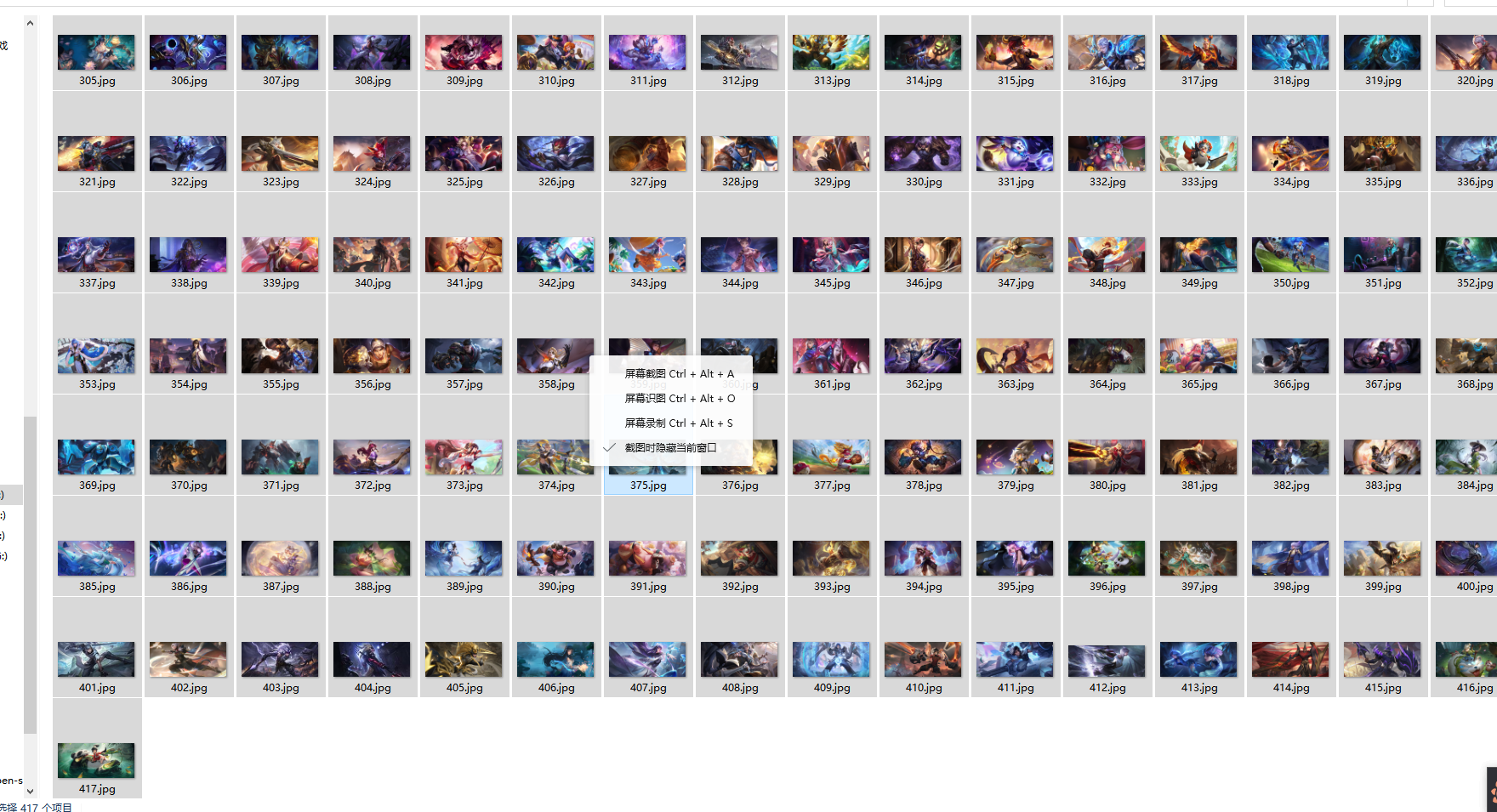
最后总共下载了大概有417张图片,后面,我们来用Python来把这些图片做成定时桌面切换
我只是记录我的学习过程,由于书读得少,可能很多地方表述或者是理解得不对,请轻喷并指正。