虽然一把年纪了,但是也追过几年的海贼王,总感觉动漫更新得比较慢,所以就想着提前预知剧情,就去看看漫画来满足自己的好奇心。每次都需要去漫画的网站一个个看,觉得还是比较麻烦,最近才学了Python,所以就想着用Python把现在更新完的漫画下载下来。
这里我们需要两个组件:
- PyQuery 主要用于解析html
- Requests 主要用于请求图片获取文件流
- selenium 加载网页
那么我们先来简单分析一下页面结构吧,
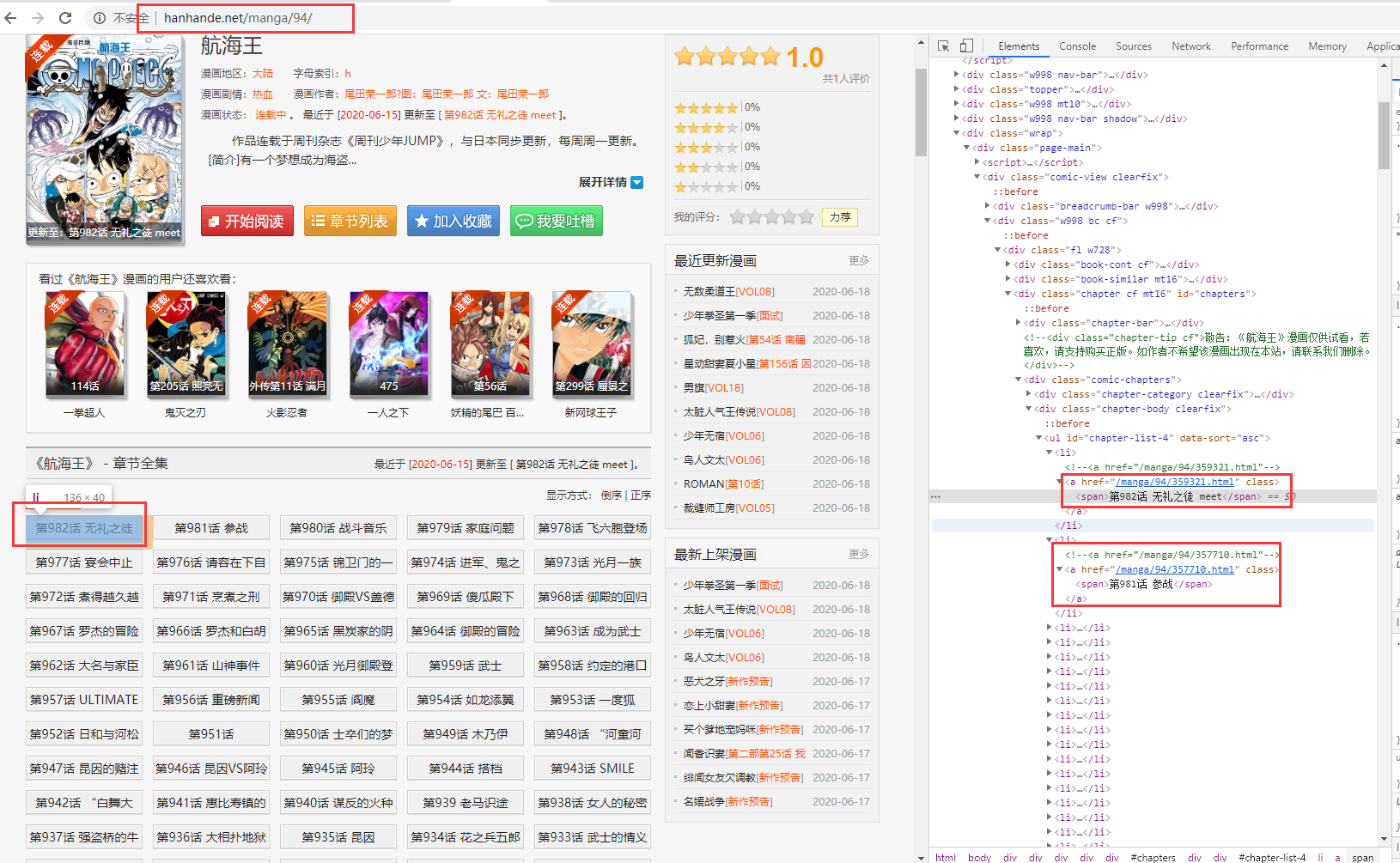
从截图中,我们可以看到每个章节就是个超链接,它的dom结构是id为chapter-list-4的ul下的li节点中,那么我们就先解析出这些超链接地址,PyQuery的安装就不在细说了,直接使用pip install PyQuery即可(不出意外的话是可以正常使用了),
from pyquery import PyQuery as pq
page = pq(url="http://www.hanhande.net/manga/94/", encoding='utf-8')
lias = page("#chapter-list-4").find('li').find('a').items()
for a in lias:
print(a.attr['href'])
print(a.text())

初步效果有了,我们再继续看看详细的动漫页面
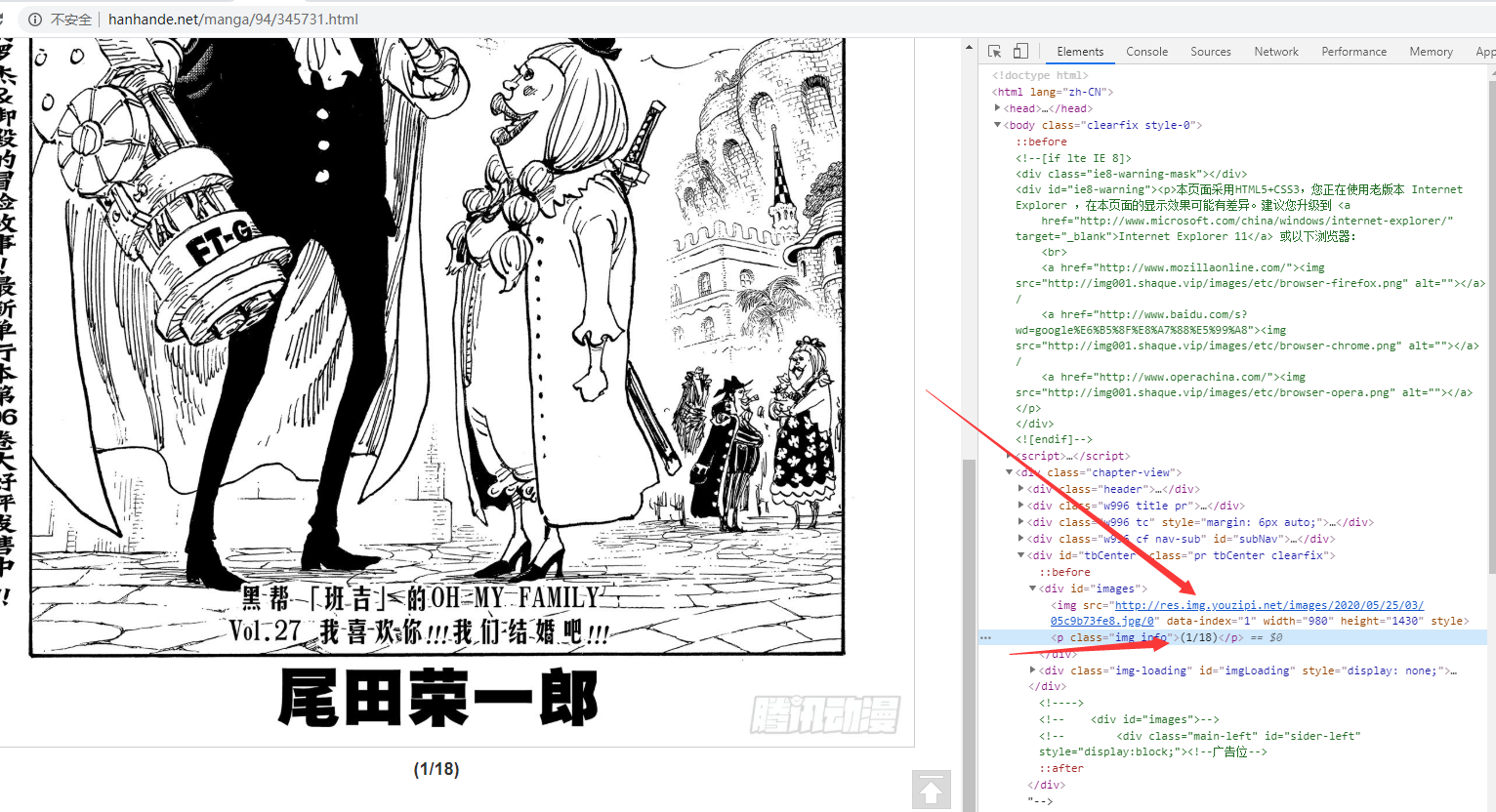 我们可以看到页面结构、图片路径以及图片页数,当我们点击下一页的时候,URL和图片都有所变化
我们可以看到页面结构、图片路径以及图片页数,当我们点击下一页的时候,URL和图片都有所变化
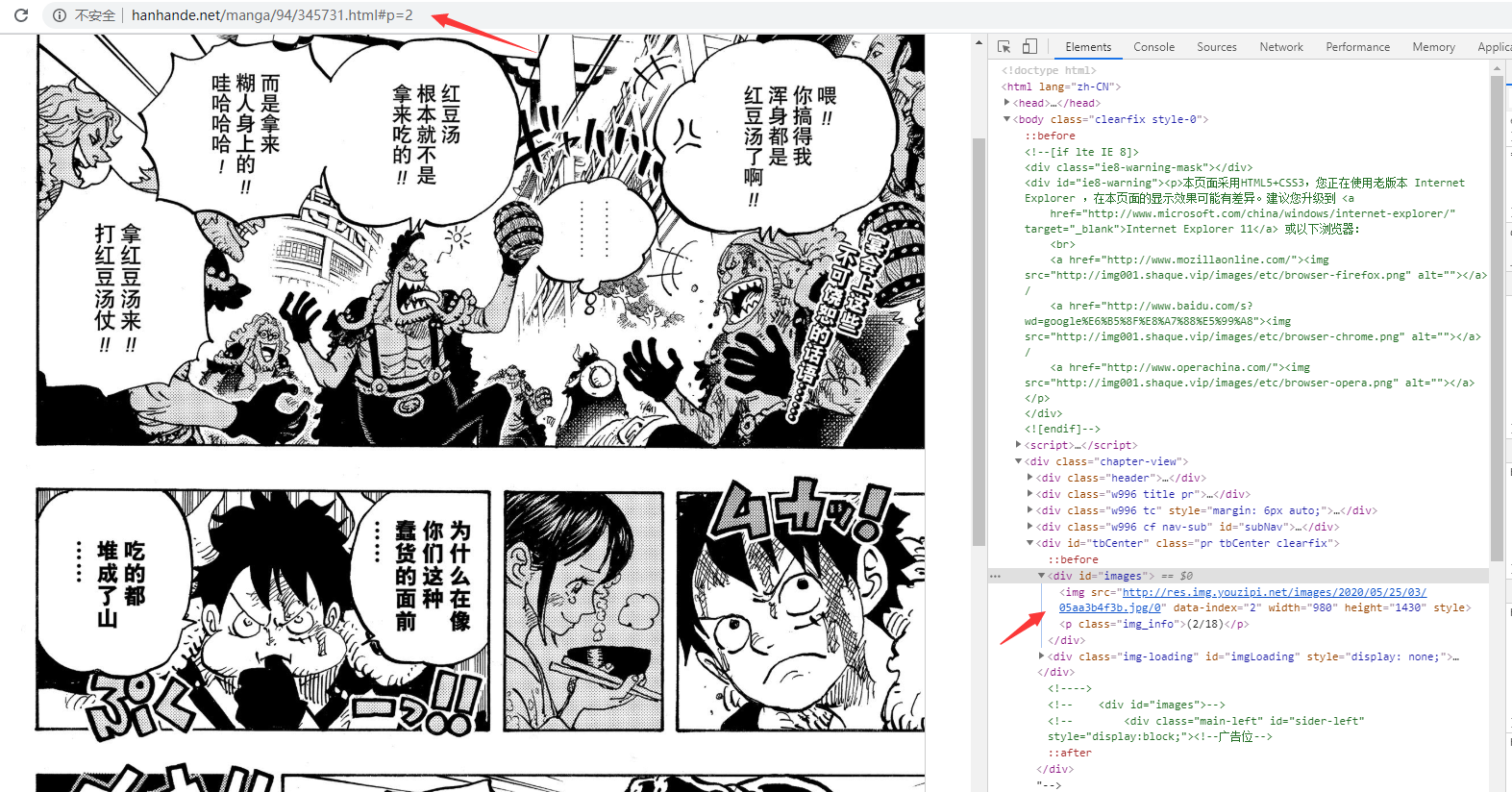 好,这里,我们就可以来获取我们的图片了
好,这里,我们就可以来获取我们的图片了
from pyquery import PyQuery as pq
from selenium import webdriver
import requests
browser = webdriver.Chrome()
browser.get('http://www.hanhande.net/manga/94/345731.html')
page = pq(browser.page_source)
images = page("#images")
img_url = images.find('img').attr.src
page_total = images.find('p').text()
print(img_url)
print(page_total.split('/')[1].replace(')', ''))
response = requests.get(img_url)
with open('1.jpg', 'wb') as f:
f.write(response.content)
执行这段脚本后,会打印出图片和页数以及在本地保存一张图片
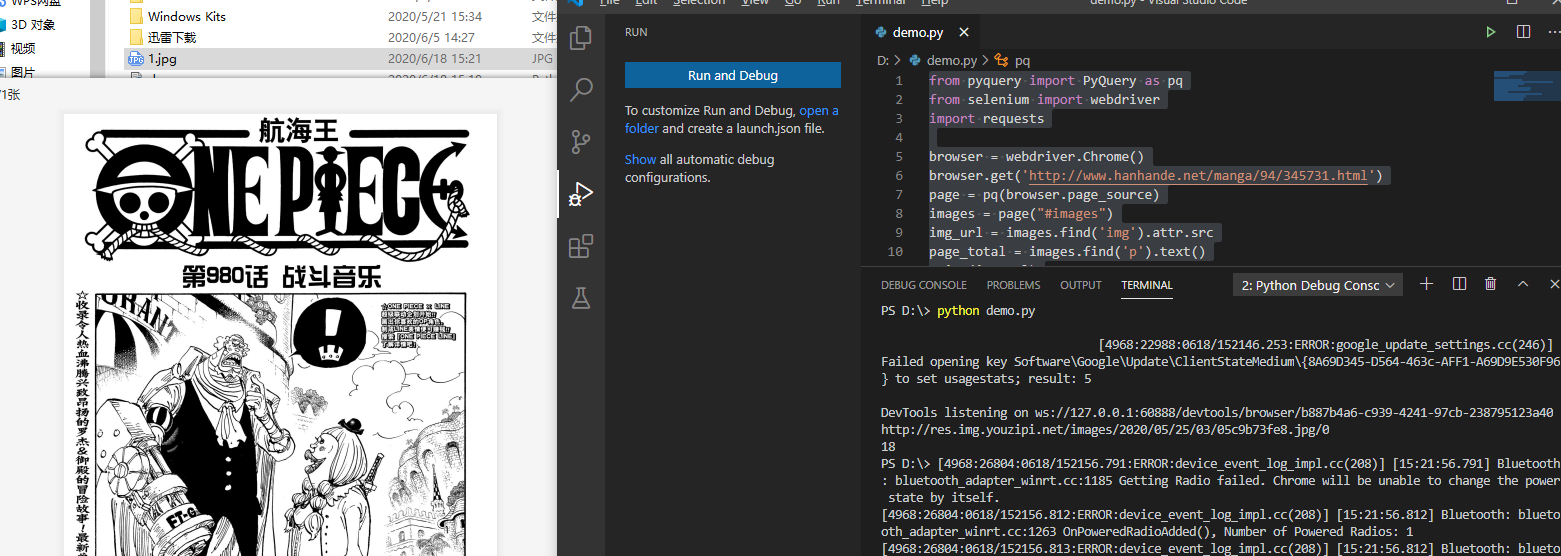
现在我们再来结合之前的获取到的地址,来全量下载吧,来看看最终代码
from pyquery import PyQuery as pq
from selenium import webdriver
import requests
import os
browser = webdriver.Chrome()
def get_pic(source_url, file_path, index):
url = source_url
if index > 1:
url = url+"#p="+str(index)
browser.get(url) # 浏览器加载的地址
browser.refresh() # 刷新浏览器
page = pq(browser.page_source)
images = page("#images")
img_url = images.find('img').attr.src
page_total = images.find('p').text()
page_total = page_total.split('/')[1].replace(')', '') # 获取漫画页数
response = requests.get(img_url)
with open(file_path+str(index)+'.jpg', 'wb') as f: # 保存图片
f.write(response.content)
if index < int(page_total):
get_pic(source_url, file_path, index+1) # 递归获取网页中的图片
def get_page(url):
page = pq(url=url, encoding='utf-8')
lias = page("#chapter-list-4").find('li').find('a').items()
for a in lias:
folder='F:/hzw/'+a.text() #
isExists=os.path.exists(folder) # 检查文件夹是否存在
if not isExists: # 如果不存在则新建文件夹
os.makedirs(folder)
get_pic('http://www.hanhande.net'+a.attr['href'], folder+"/", 1)
get_page('http://www.hanhande.net/manga/94/')
现在执行脚本就可以看到程序正在逐一下载图片哟
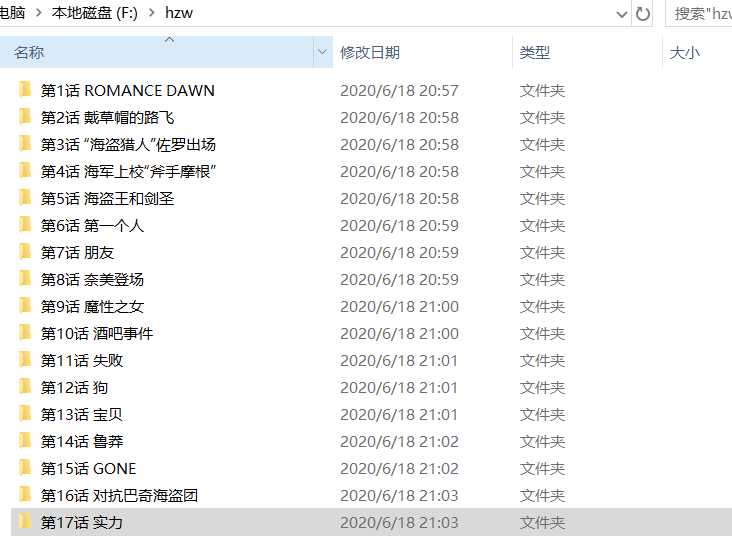
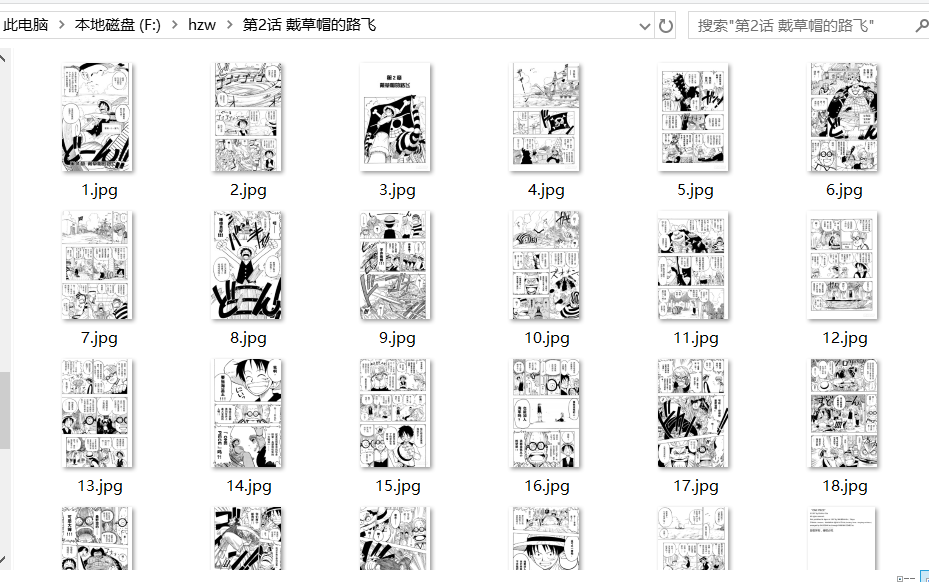 是不是感觉有点意思呢?
是不是感觉有点意思呢?
我只是记录我的学习过程,由于书读的少,可能很多地方表述或者是理解得不对,请轻喷并指正。