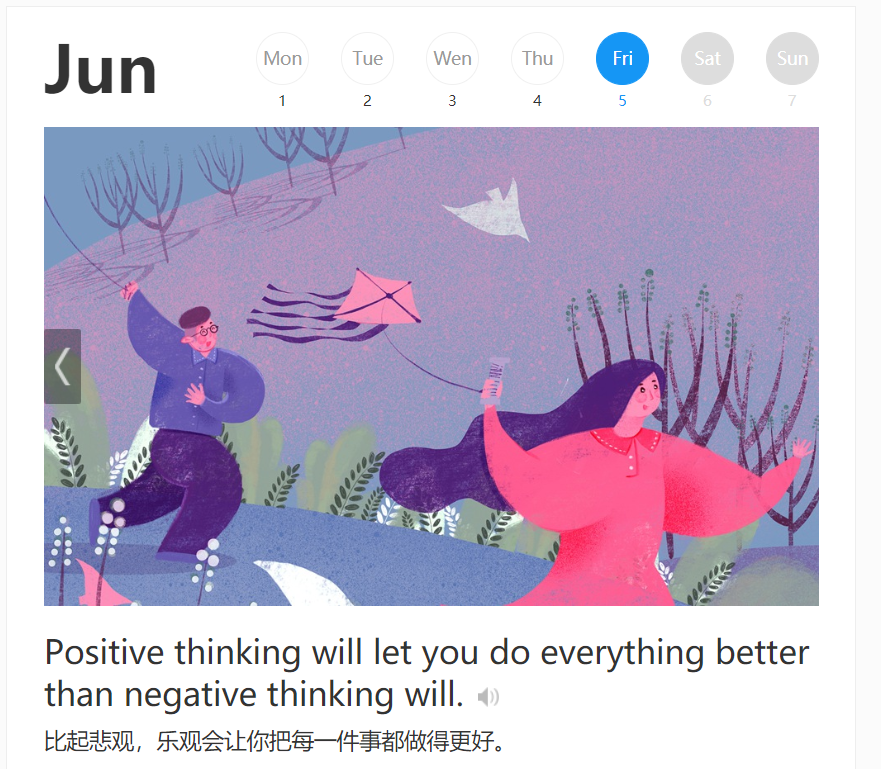
其实金山词霸每日一句已经出来很久了,但是我都不知道,今天去金山词霸的官网看了看,感觉这些句子都挺不错的,所以就想着把它们给存下来。
我大概看了一下他的页面,请求的敏感数据是加密的,页面是基于请求的数据动态渲染的,去解析结构的话,会比较花时间,这里我就使用selenium来简化操作,它可以模拟浏览器,直接把数据渲染成最终的展示出来的页面,然后,直接解析最终的html就可以得到最终的结果。
安装selenium
pip install selenium
 因为是这里是用的google浏览器
因为是这里是用的google浏览器版本 83.0.4103.97(正式版本) (32 位),所以
这里我们需要去http://npm.taobao.org/mirrors/chromedriver下载对应的chromedriver驱动,然后解压到Python的安装目录。
如果不指定自己的安装路径,可以在cmd中执行where python命令来查找
C:\Users\lenovo>where python
D:\Programs\Python\Python38-32\python.exe
C:\Users\lenovo\AppData\Local\Microsoft\WindowsApps\python.exe
把我们下载的chromedriver复制到对应的目录,我这里是D:\Programs\Python\Python38-32\
使用的selenium
那么这里先简单的写几句代码
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('http://news.iciba.com/views/dailysentence/daily.html#!/detail/title/2020-06-05')
print(browser.page_source)
我们运行python demo.py就会看到这样的效果
 这里我需要它的图片、英文和汉译,我们来看看它的网页元素结构
这里我需要它的图片、英文和汉译,我们来看看它的网页元素结构
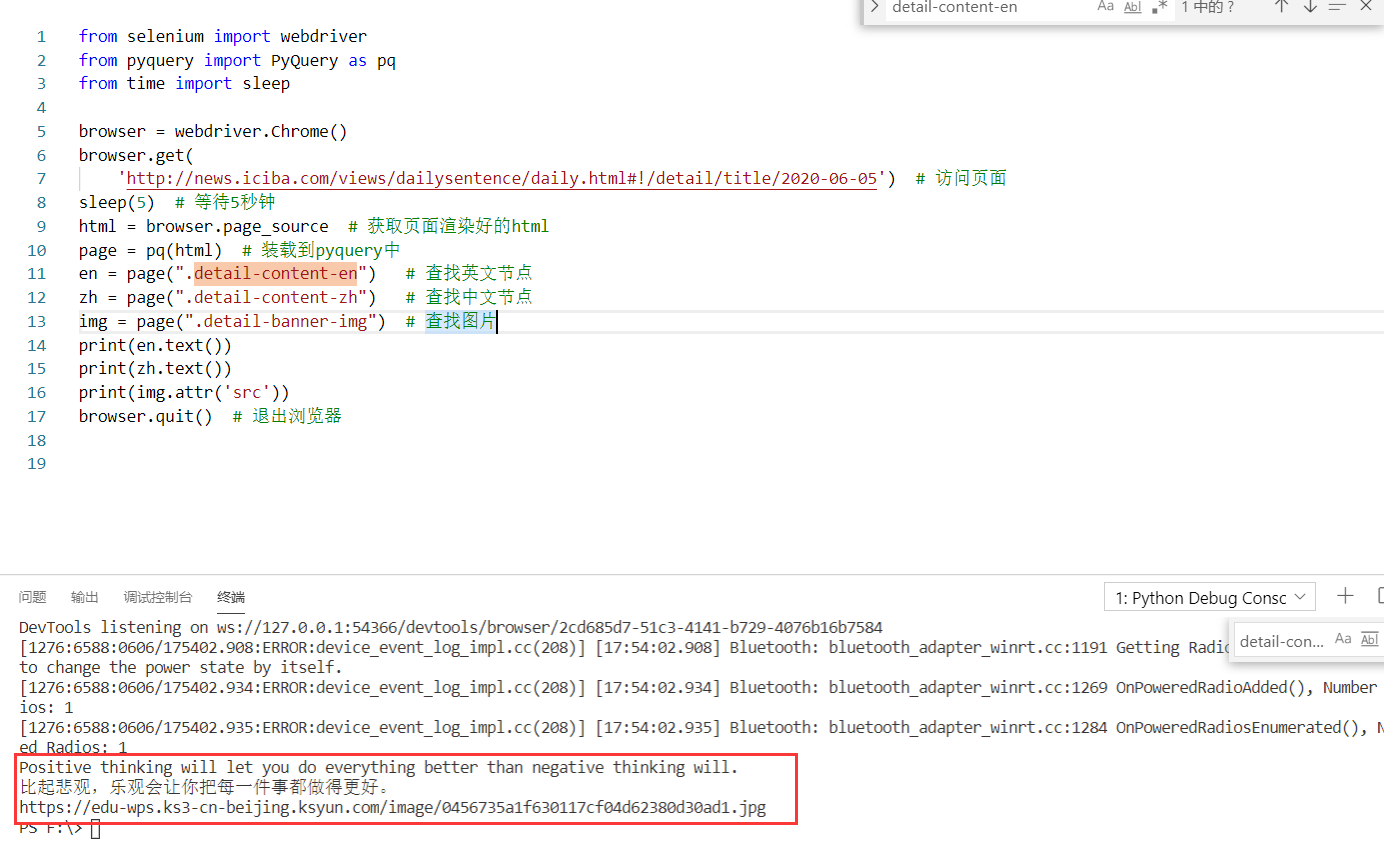
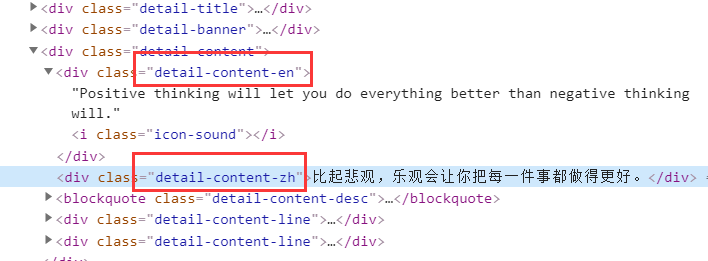 它的英文和汉译分别在
它的英文和汉译分别在detail-content-en和detail-content-zh两个class节点中,这里我们需要借助另外一个插件来解析selenium获取到的html,它就是PyQuery,先执行pip install PyQuery 把它安装下来,现在我们来开始获取他的英文内容、汉译内容以及图片地址
from selenium import webdriver
from pyquery import PyQuery as pq
from time import sleep
browser = webdriver.Chrome()
browser.get(
'http://news.iciba.com/views/dailysentence/daily.html#!/detail/title/2020-06-05') # 访问页面
sleep(5) # 等待5秒钟
html = browser.page_source # 获取页面渲染好的html
page = pq(html) # 装载到pyquery中
en = page(".detail-content-en") # 查找英文节点
zh = page(".detail-content-zh") # 查找中文节点
img = page(".detail-banner-img") # 查找图片
print(en.text())
print(zh.text())
print(img.attr('src'))
browser.quit() # 退出浏览器
 现在,我们来把每日一句的内容保存下来
现在,我们来把每日一句的内容保存下来
from selenium import webdriver
from pyquery import PyQuery as pq
import time
import requests
cur_date = time.strftime("%Y-%m-%d", time.localtime(time.time())) # 取当前日期
browser = webdriver.Chrome()
browser.get(
'http://news.iciba.com/views/dailysentence/daily.html#!/detail/title/'+cur_date) # 访问页面
time.sleep(5) # 等待5秒钟
html = browser.page_source # 获取页面渲染好的html
page = pq(html) # 装载到pyquery中
en = page(".detail-content-en") # 查找英文节点
zh = page(".detail-content-zh") # 查找中文节点
img = page(".detail-banner-img") # 查找图片
with open('D:/ciba/'+cur_date+'.txt', 'wb') as file: # 将内容写入txt文本
file.write(en.text().encode())
file.write("\n".encode())
file.write(zh.text().encode())
img_url = img.attr('src')
r = requests.get(img_url)
with open('D:/ciba/'+cur_date+'.jpg', 'wb')as f: # 将图片保存成文件
f.write(r.content)
browser.quit() # 退出浏览器
现在,我们执行python demo.py,就可以得到这样的效果

是不是感觉有点意思?
我只是记录我的学习过程,由于书读的少,可能很多地方表述或者是理解得不对,请轻喷并指正。